
字符集所占java字节数整理
常用字符集占字节数码表整理
| 常用字符集 | 所占字节数 | 英文/字节 | 中文/字节 | 说明 |
|---|---|---|---|---|
| ASCII | 单字节(0x00-0x7F) | 1 | 不支持中文 | 国际标准,ISO/IEC 646 |
| Latin1(别名ISO8859-1) | 单字节(0x00-0xFF) | 1 | 不支持中文 | 向下兼容ASCII,还包括西欧语言,希腊语,泰语,阿拉伯语,希伯来语 |
| ANSI | 单双字节(0x0000-0xFFFF)单字节仅表示ASCII | 1 | 2 | 不是单一明确的字符编码,是对不同国家和地区不同编码的一个统称(如GB2312,GBK,BIG5,Shift_JS) |
| GB2312 | 单双字节(0x0000-0xFFFF) 单字节仅表示ASCII | 1 | 2 | 标准简体中文字符集,1980年发布,1981年5月实施,收录6763个汉字GB1300双字节(0x0000-0xFFFF)121993年发布,收录中国大陆、台湾、日本及韩国通用字符集的汉字,总共有20,902个.因为没有兼容GB2312,并没有得到广泛应用,如今已被废弃 |
| Big5 | 双字节(0x0000-0xFFFF) | 1 | 2 | 大五码或五大码,共收录13060个汉字,是繁体中文编码 |
| GBK | 双字节(0x0000-0xFFFF) | 1 | 2 | 向下兼容GB2312,汉字内码扩展规范,只是作为技术规范,并非国家正式标准 |
| Unicode | 四字节(U+0000-U+10FFFF) | 4 | 4 | 万国码,统一码联盟在1991年发布,共分为17个平面,0号平面为BMP |
| UCS、UCS-2、USC=4 | UCS-2(双字节)UCS-4(四字节) | 2、4 | 2、4 | ISO/IEC 10646标准 |
| Utf-8(变长) | 1-4字节 | 1 | 3 | 现在最常用的字符集 |
| Utf-16、UTF-32 | UTF-16(2、4字节),UTF-32(4字节) | 4 | 4 | |
| LE(little endian)、BE(big endian)、BOM(byte order mark) | UTF-16和UTF-32 的大端字节序和小端字节序 BOM(UTF-8:EF BB BF;UTF-16 LE: FF FE;UTF-16 BE: FE FF;UTF-32 LE: FF FE 00 00;UTF-32 BE: 00 00 FE FF) | 无 | 无 | LE和BE 双字节或四字节高地位排序 BOM 字节排序标记(window的软件一般都会有BOM,而其他系统默认都没有,window要兼容ANSI,防止出错) |
| 内码 外码 代码页 | 代码页:GBK为936;UTF-8为65001 | 无 | 无 | 内码指的是操作系统的字符编码;外码指的是用户从键盘上键入汉字所使用的汉字编码. 代码页:windows使用代码页来各个国家地区字符编码. |
java 代码测试方法
1 |
|
运行结果如图: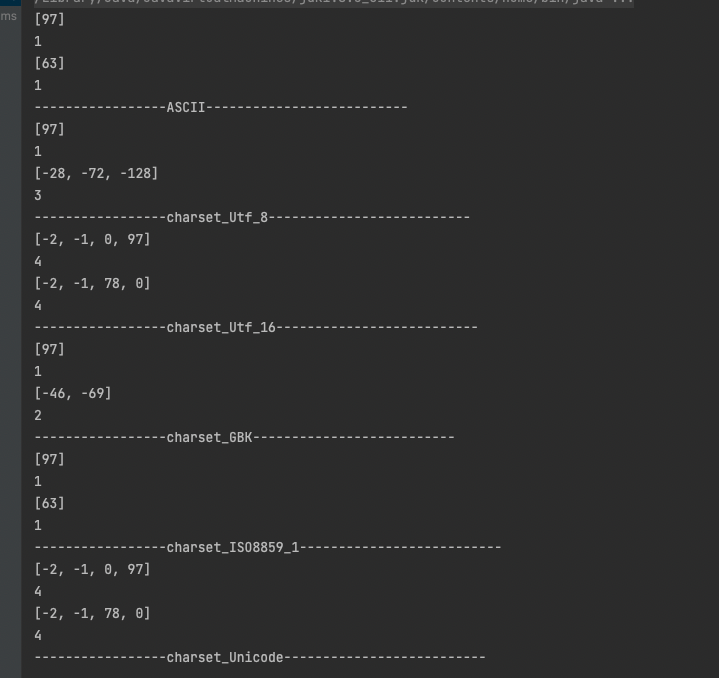
将b的字面值替换为“䶮”,运行结果如下图: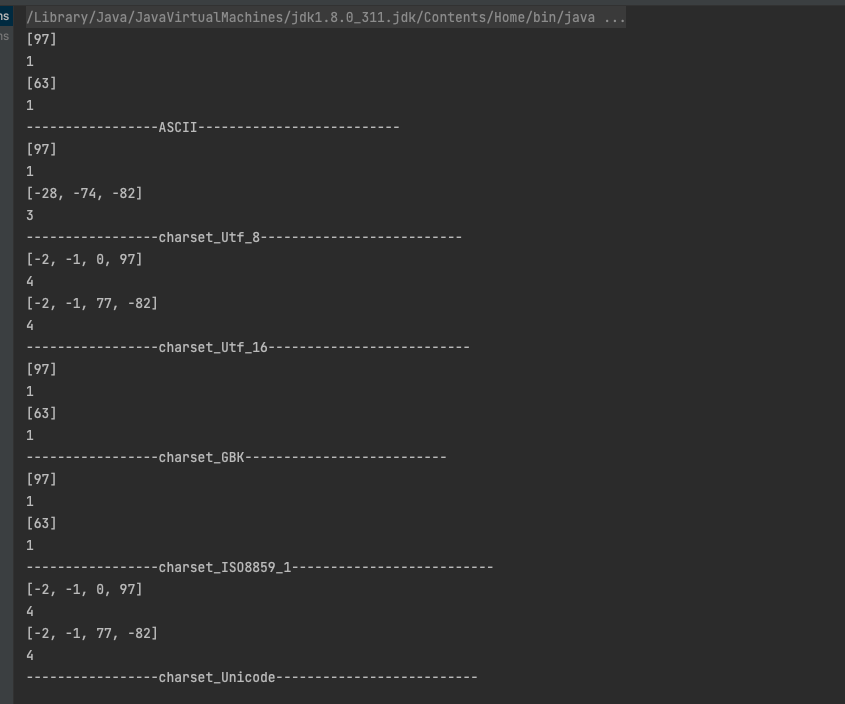
将a的字面值替换为“A”,将b的字面量替换为“天”,运行结果如下图: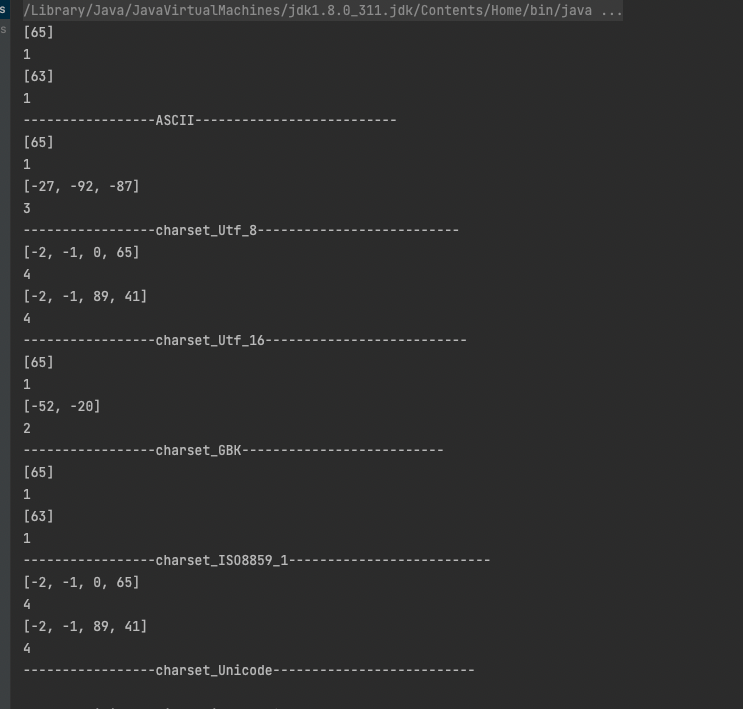
windows活动页代码和字符集的对应关系
| 活动页代码(active code page) | 字符集 |
|---|---|
| 437 | 美国 |
| 708 | 阿拉伯文(ASMO 708) |
| 720 | 阿拉伯文(DOS) |
| 850 | 多语言(拉丁文 I) |
| 852 | 中欧(DOS) - 斯拉夫语(拉丁文 II) |
| 855 | 西里尔文(俄语) |
| 857 | 土耳其语 |
| 860 | 葡萄牙语 |
| 861 | 冰岛语 |
| 862 | 希伯来文(DOS) |
| 863 | 加拿大 - 法语 |
| 865 | 日耳曼语 |
| 866 | 俄语 - 西里尔文(DOS) |
| 869 | 现代希腊语 |
| 874 | 泰文(Windows) |
| 932 | 日文(Shift-JIS) |
| 936 | 中国 - 简体中文(GB2312) |
| 949 | 韩文 |
| 950 | 繁体中文(Big5) |
| 1200 | Unicode |
| 1201 | Unicode (Big-Endian) |
| 1250 | 中欧(Windows) |
| 1251 | 西里尔文(Windows) |
| 1252 | 西欧(Windows) |
| 1253 | 希腊文(Windows) |
| 1254 | 土耳其文(Windows) |
| 1255 | 希伯来文(Windows) |
| 1256 | 阿拉伯文(Windows) |
| 1257 | 波罗的海文(Windows) |
| 1258 | 越南文(Windows) |
| 20866 | 西里尔文(KOI8-R) |
| 21866 | 西里尔文(KOI8-U) |
| 28592 | 中欧(ISO) |
| 28593 | 拉丁文 3 (ISO) |
| 28594 | 波罗的海文(ISO) |
| 28595 | 西里尔文(ISO) |
| 28596 | 阿拉伯文(ISO) |
| 28597 | 希腊文(ISO) |
| 28598 | 希伯来文(ISO-Visual) |
| 38598 | 希伯来文(ISO-Logical) |
| 50000 | 用户定义的 |
| 50001 | 自动选择 |
| 50220 | 日文(JIS) |
| 50221 | 日文(JIS-允许一个字节的片假名) |
| 50222 | 日文(JIS-允许一个字节的片假名-SO/SI) |
| 50225 | 韩文(ISO) |
| 50932 | 日文(自动选择) |
| 50949 | 韩文(自动选择) |
| 51932 | 日文(EUC) |
| 51949 | 韩文(EUC) |
| 52936 | 简体中文(HZ) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
参考博客:
不错的博客,整理概括编码
https://blog.csdn.net/K346K346/article/details/52312953
GBK、GB2312、ISO-8859-1的区别(mac系统,file指令识别不了的文件编码会显示ISO-8859-1格式)
https://www.cnblogs.com/x_wukong/p/3675832.html
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 小天的博客!
评论