staticbyte[] encode(char[] ca, int off, int len) { //该方法中主要通过该方法获取字符集名称 Stringcsn= Charset.defaultCharset().name(); try { // use charset name encode() variant which provides caching. return encode(csn, ca, off, len); } catch (UnsupportedEncodingException x) { warnUnsupportedCharset(csn); } try { return encode("ISO-8859-1", ca, off, len); } catch (UnsupportedEncodingException x) { // If this code is hit during VM initialization, MessageUtils is // the only way we will be able to get any kind of error message. MessageUtils.err("ISO-8859-1 charset not available: " + x.toString()); // If we can not find ISO-8859-1 (a required encoding) then things // are seriously wrong with the installation. System.exit(1); returnnull; } }
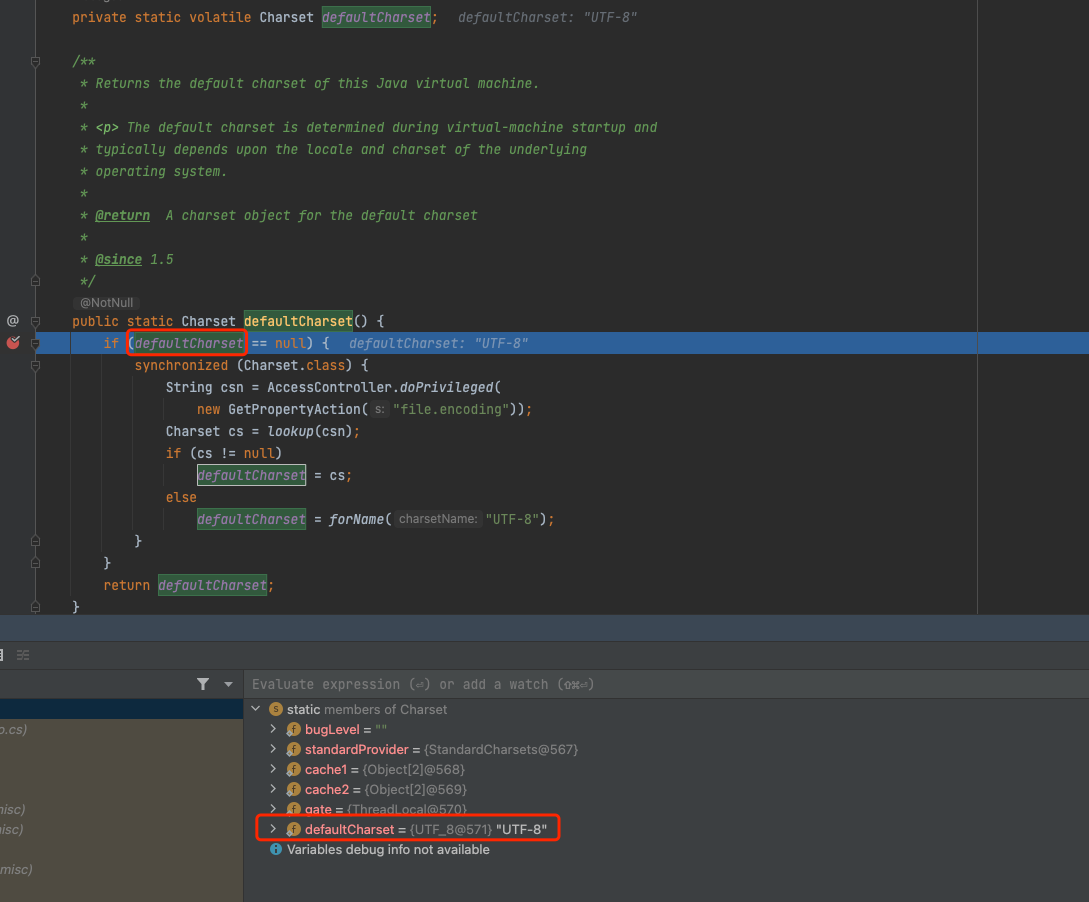
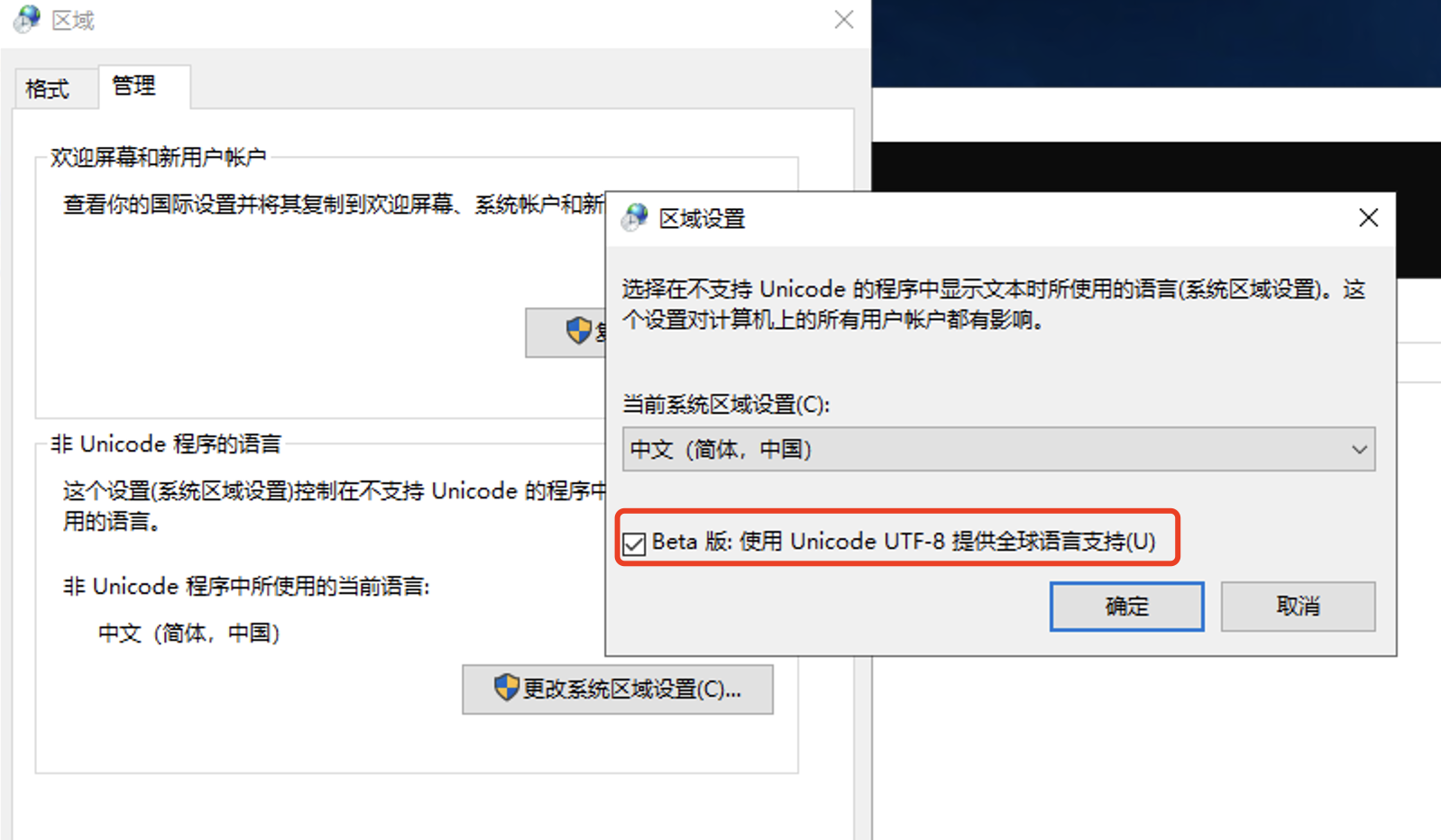
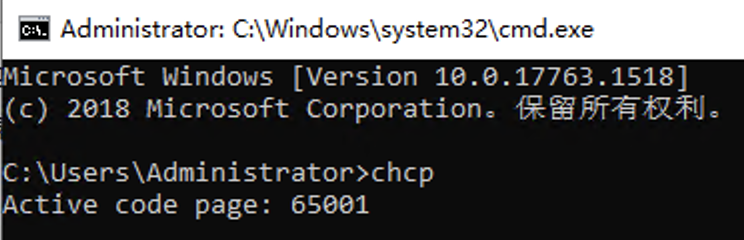
/** * Returns the default charset of this Java virtual machine. * 返回此 Java 虚拟机的默认字符集。 * <p> The default charset is determined during virtual-machine startup and * typically depends upon the locale and charset of the underlying * operating system. * 默认字符集在虚拟机启动期间确定,通常取决于底层操作系统的区域设置和字符集。 * @return A charset object for the default charset * * @since 1.5 */ publicstatic Charset defaultCharset() { if (defaultCharset == null) { synchronized (Charset.class) { Stringcsn= AccessController.doPrivileged( newGetPropertyAction("file.encoding")); Charsetcs= lookup(csn); if (cs != null) defaultCharset = cs; else defaultCharset = forName("UTF-8"); } } return defaultCharset; }